Dify搭建本地RAG知识库
AI发展的迅猛,各行各业都在努力与Ai靠拢,企图乘上这趟快车,同时AI的发展也让大家看到了广阔的前景,这并不是局限某个行业的红利,它已经被广泛应用于各个领域,包括金融、医疗、物流、智能制造等等。我们仍处于发展与探索之中。
其实基于深度学习的AI网络应用一直在发展研究,如利用RNN循环神经网络(Recurrent Neural Networks)与LSTM长短时记忆网络(Long Short-Term Memory)进行网络故障预测或网络安全攻击预测。在17/18年左右开始便开始有众多AIOPS相关研究与发展,如国内清华大学的裴丹教授\南开大学的张圣林教授关于交换机、网络等故障预测、AIOPS也有众多科研项目在这段时间开始。
但个人认为相关技术用于推广普及使用仍有一定的的难度,AI相关应用最关键的点在于数据集,这直接关乎到模型的训练效果,而现实网络当中,首先是高质量、标注好的大数据集构建难度大且成本高,尤其是在涉及敏感信息或领域。而且也不可能随便共享复用,数据隐私性是关键问题。而且目前常规的网络运维监控通常使用zabbix及Prometheus采集网络设备信息,信息繁杂,噪声过大,不可能直接用作训练集,而各自网络环境不同,数据清洗仍是一大考验。其次是各网络厂商之间壁垒较高,系统,命令格式,硬件规格差异性较大,私有特性与协议也各有不同,较难以一个规范化标准来推广应用。
23年AI的爆发也得益于之前长时间发展的积累,ChatGPT的横空出世第一次让普罗大众直观的感受到AI所带来的冲击,GPT模型是基于Transformer结构的一种语言模型,Transformer模型是现代深度学习的前沿技术之一。它摆脱了传统循环神经网络(RNN)和卷积神经网络(CNN)的局限性,引入了注意力机制,以其卓越的文本处理和生成能力,引领了自然语言处理(NLP)的革命。如检索增强生成(RAG)技术的应用。
通过RAG技术来搭建知识库,也是目前最容易落地的AI项目,我认为其在AI网络应用中仍有发展空间,因为知识库还有良好的兼容性与其他技术相结合,不仅仅是对于网工的帮助,也能为整个企业带来广泛的价值。我们设想一个场景,通过RAG知识库的本地部署,针对内部资料进行训练首先可以确保一个数据的保密性与安全性。其次,我们可以分门别类建立多个小型的知识库如售前可以是一些产品价目表,招标参数,产品详细介绍,各行业相关解决方案材料,售后是一些产品配置手册,命令行指导手册等等,市场部可以设置知识库为公司相关介绍,相关产品彩页,市场活动资料等等。建立不同的知识库可以通过单点登录设置分权分域,而且可以降低模型推理所需的硬件成本。建立知识库后可以通过聊天助手或AI Agent对接,通过自然语言聊天实现与人的交互。
例如:
- 售前相关:当售前收到项目需求后,与AI Agent进行沟通,将设备的相关需求参数输入Agent,Agent根据知识库给出过往项目组网与解决方案进行参考,当人为确定组网架构时,Agent通过查询知识库匹配并给出推荐产品与相关价格。
- 售后相关:在售前确认相关解决方案的同时,Agent根据组网架构与产品给出建议性配置于售后,如OSPF、VLAN划分,堆叠配置或VRRP。售后可以进行进一步沟通与明确具体需求让Agent从知识库内调用相关的产品配置命令并输出,用于ZTP配置或一键导入预配进行开局。
- 市场部门相关:可以将公司介绍与简单产品介绍生成知识库,以聊天助手调用知识库的形式嵌入到公司官网内,可供客户浏览网页时进行初步了解。
实际部署案例:Grafana、美团智能客服
Dify
官网上定义自身为生成式 AI 应用创新引擎,一个开源的 LLM 应用开发平台。提供从 Agent 构建到 AI workflow 编排、RAG 检索、模型管理等能力,轻松构建和运营生成式 AI 原生应用。并且毫不避讳的表示“比 LangChain 更易用”
备注:LangChain是一个开源库,用于构建和运行基于语言模型的应用程序。它是由语言模型(如GPT)的用户和开发者设计的,旨在简化大型语言模型(LLM)的使用和集成过程。但是他更偏向于底层代码化设计,我认为更针对与开发者。
有公有云解决方案与本地化社区版
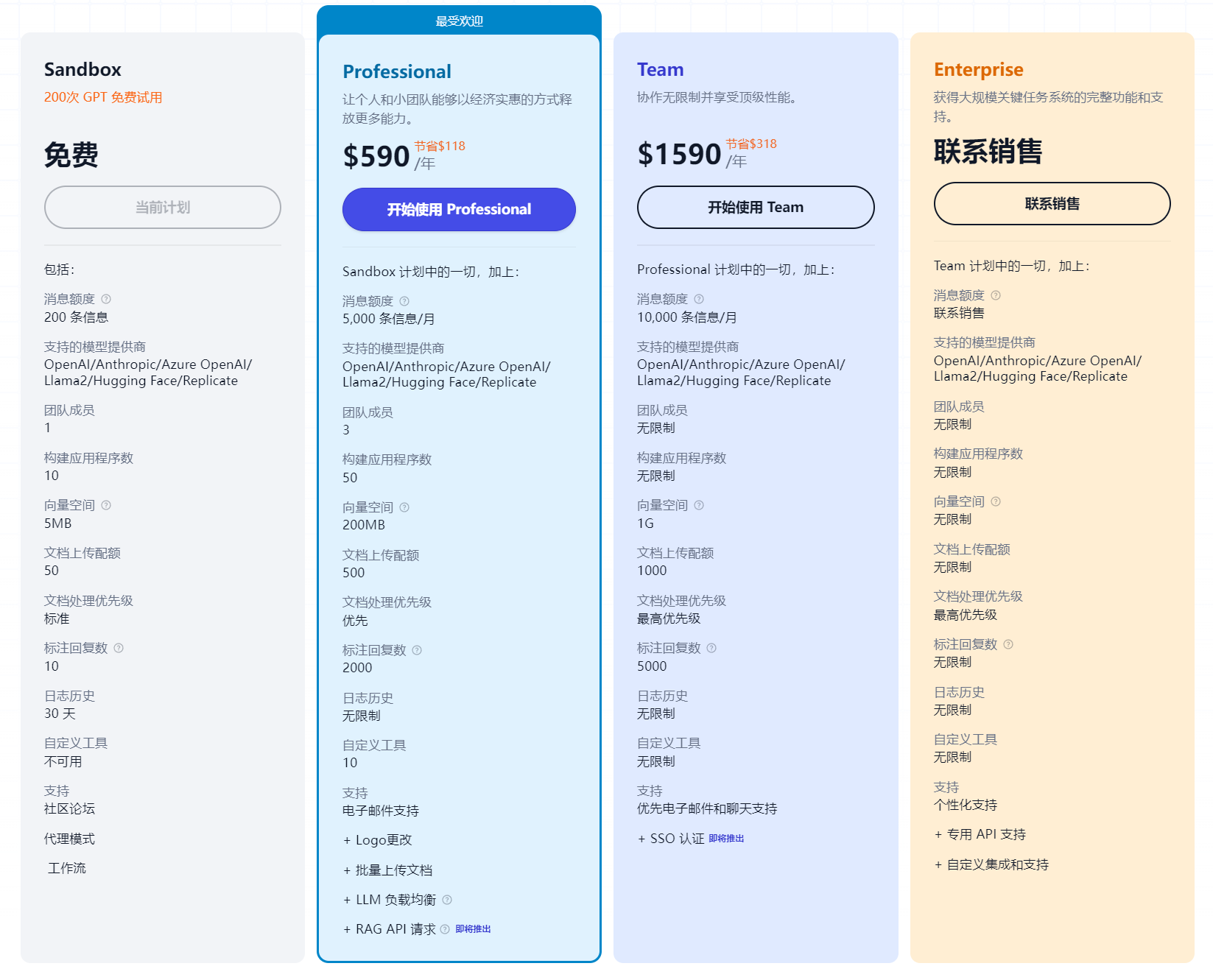
平台搭建
目前DIfy release稳定版本为0.7.3
推荐使用Docker compose来部署,一键操作,快速入手
git clone https://github.com/langgenius/dify.git |
设置代理(可选)
git config --global http.proxy http://ipaddress:port |
查看已有代理
git config --global -l |
或使用单次代理
git clone -c http.proxy="http://ipaddress:port" https://github.com/langgenius/dify.git |
进入 Dify 源代码的 Docker 目录
cd dify/docker |
复制环境配置文件
cp .env.example .env |
启动Dify
docker compose up -d |
目前需设置Docker代理或加速镜像
加速镜像
sudo mkdir -p /etc/docker |
代理设置
sudo mkdir -p /etc/docker |
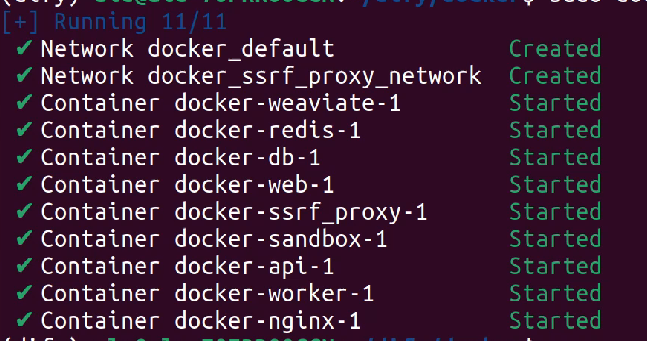
可以看到用到的一些数据库以及中间件。
升级DIfy
cd dify/docker |
WEB输入IP地址,默认开放80端口,监听0.0.0.0,初次登陆设置管理员账号即可开始使用

快速生成自己的聊天助手
在打造自己的AI之前需要调用第三方或者部署本地大模型。可以在web界面直接接入相关模型。我们从简单快速的入手,先调用第三方API尝试生成自己的聊天助手。
在设置的模型提供商处,有预设的接口方便直接调用第三方大模型的API进行接入。
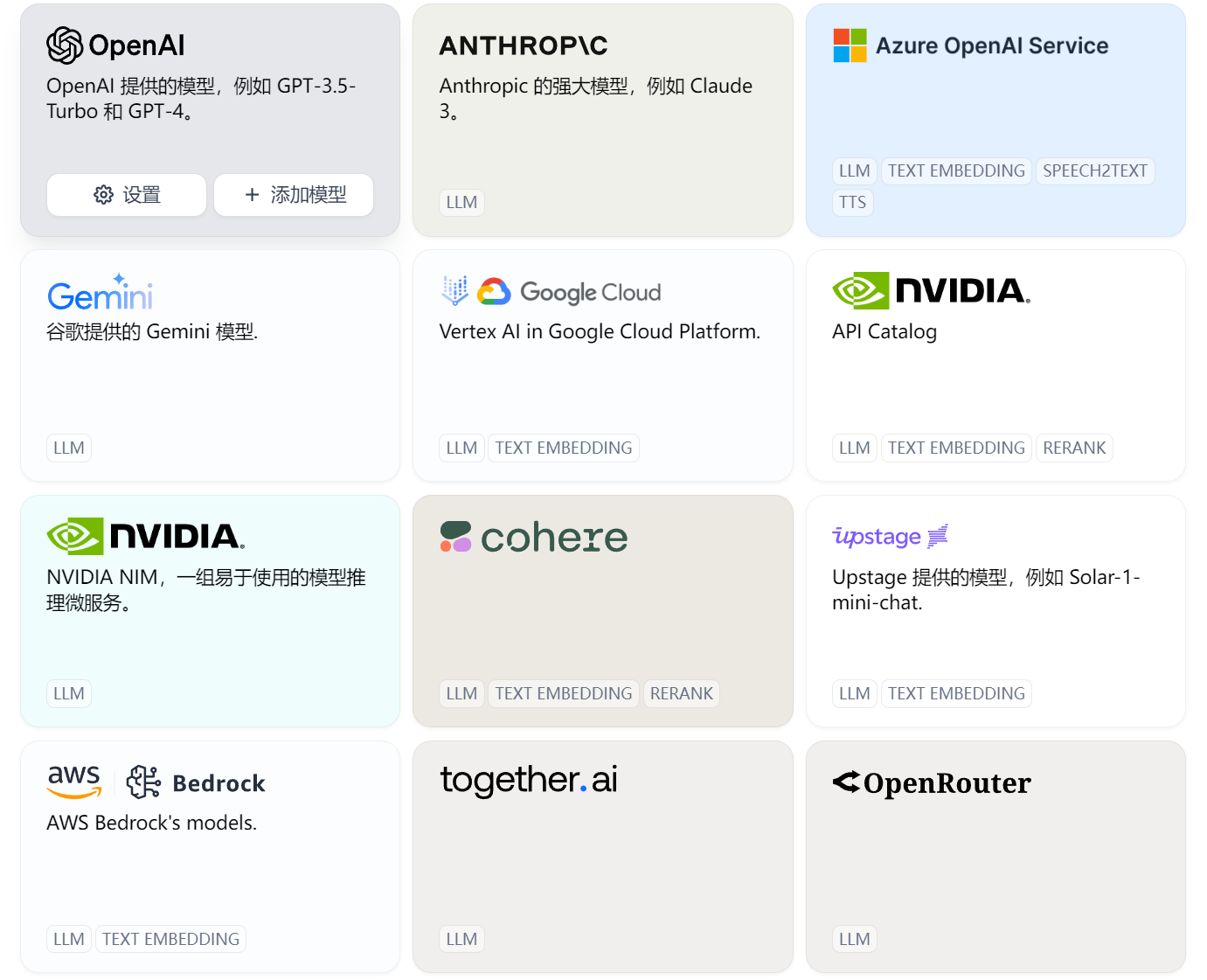
调用第三方AI api:可以从国产及免费的几款模型进行尝试。如Kimi、GLM(智谱清言)、Spark(讯飞星火)。
讯飞星火
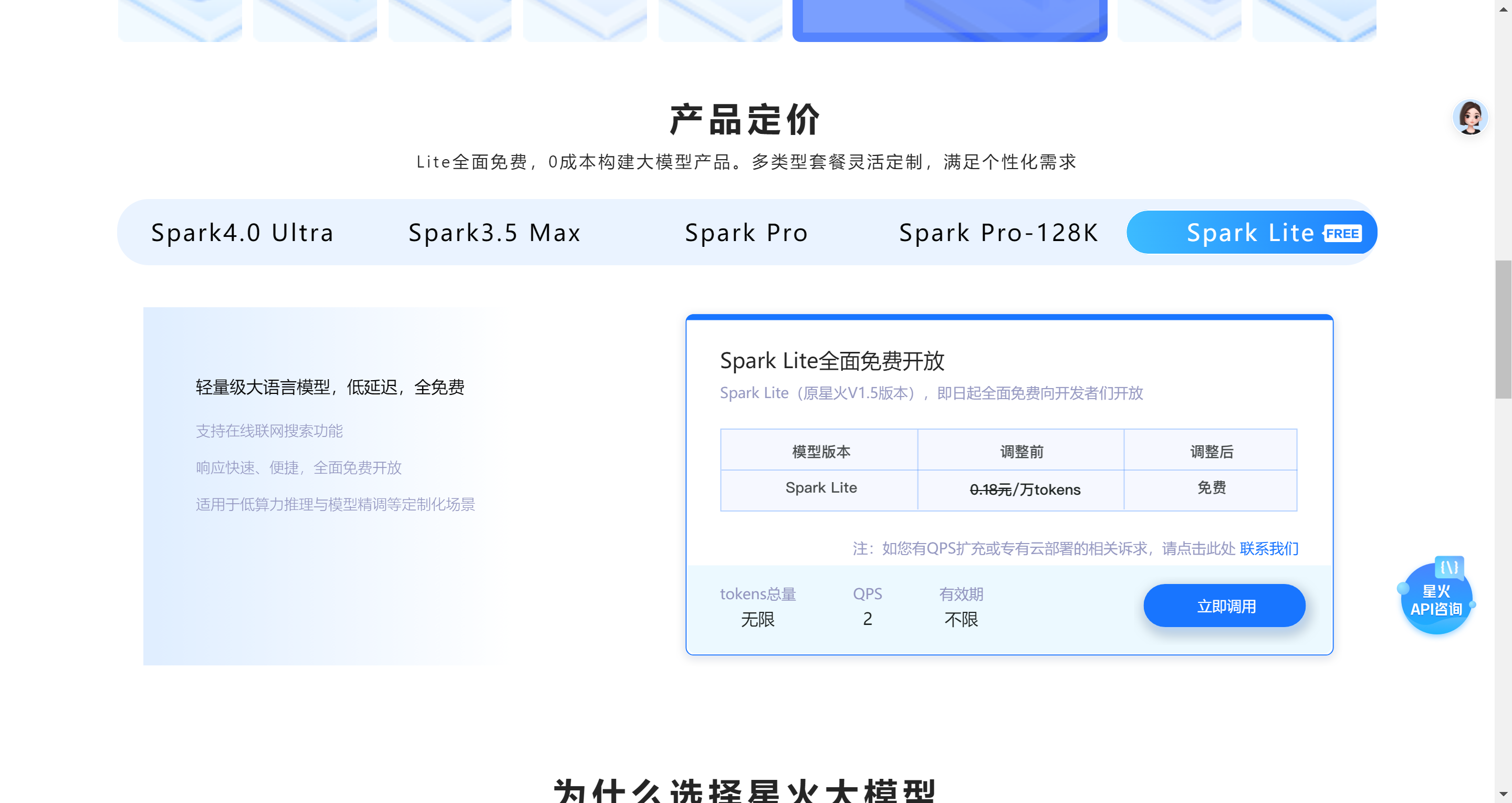
选择模型并获取API
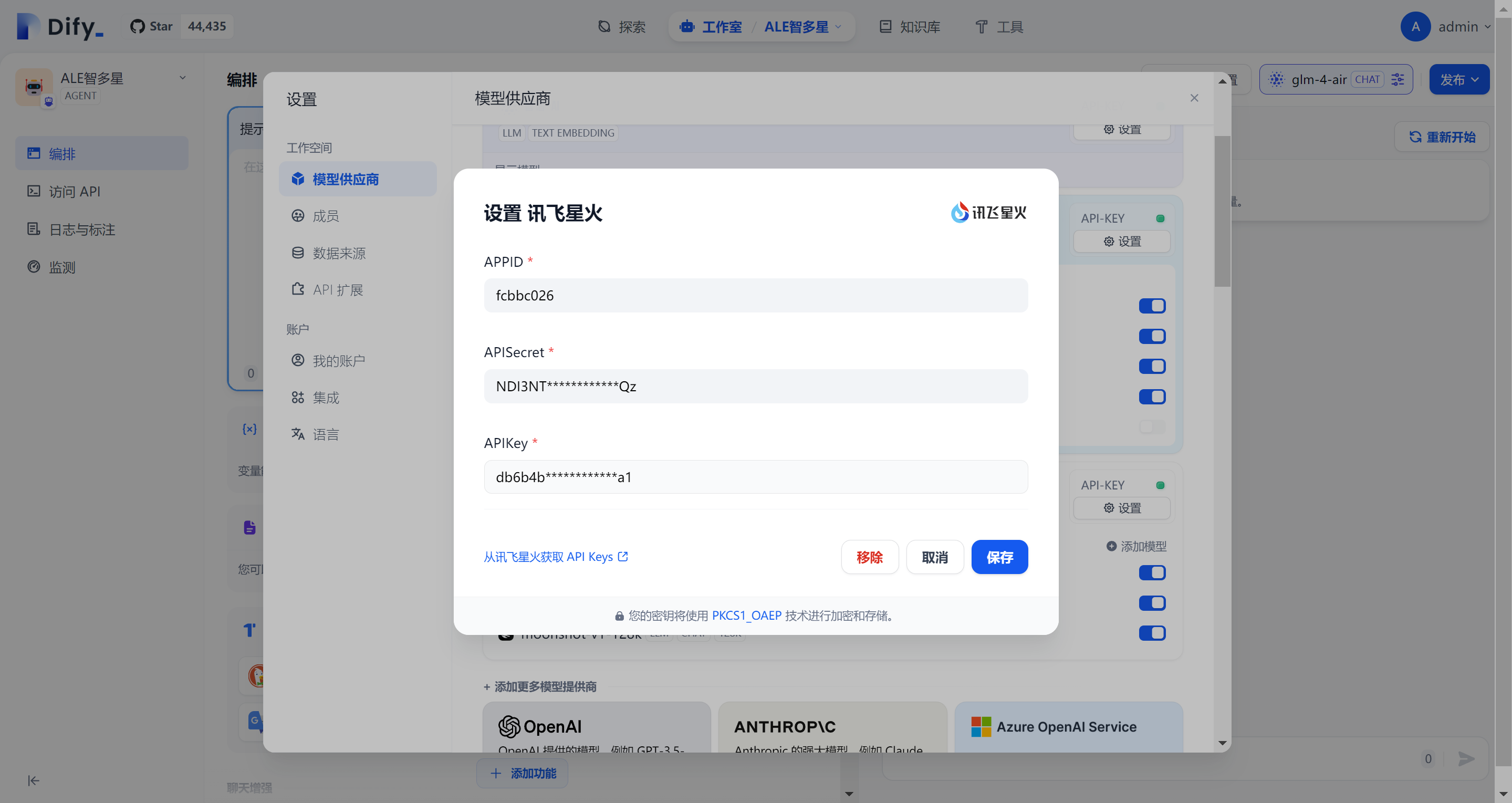
月之暗面(Kimi)设置:
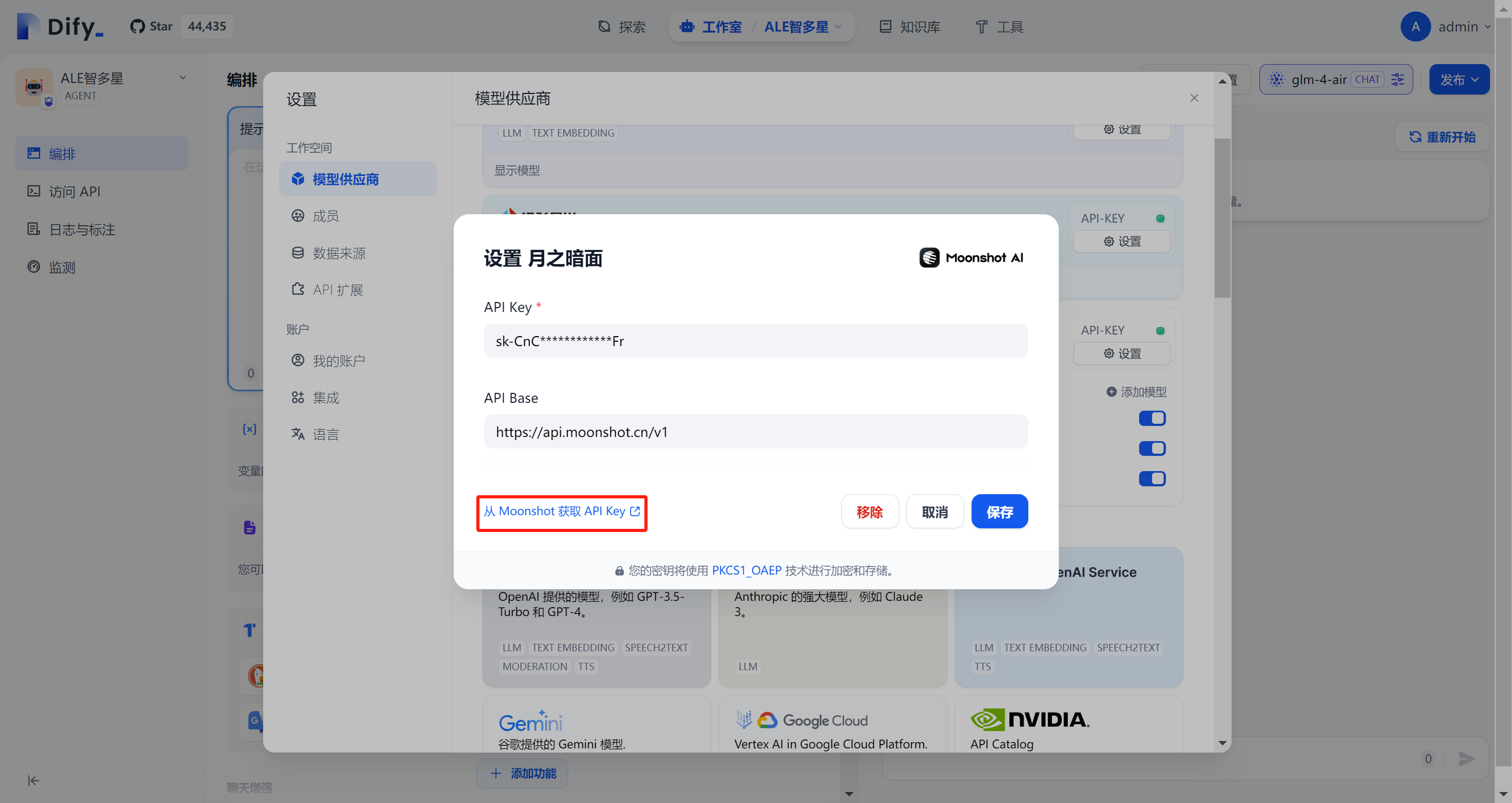
点击链接即可调整月之暗面开发者平台,新建API即可
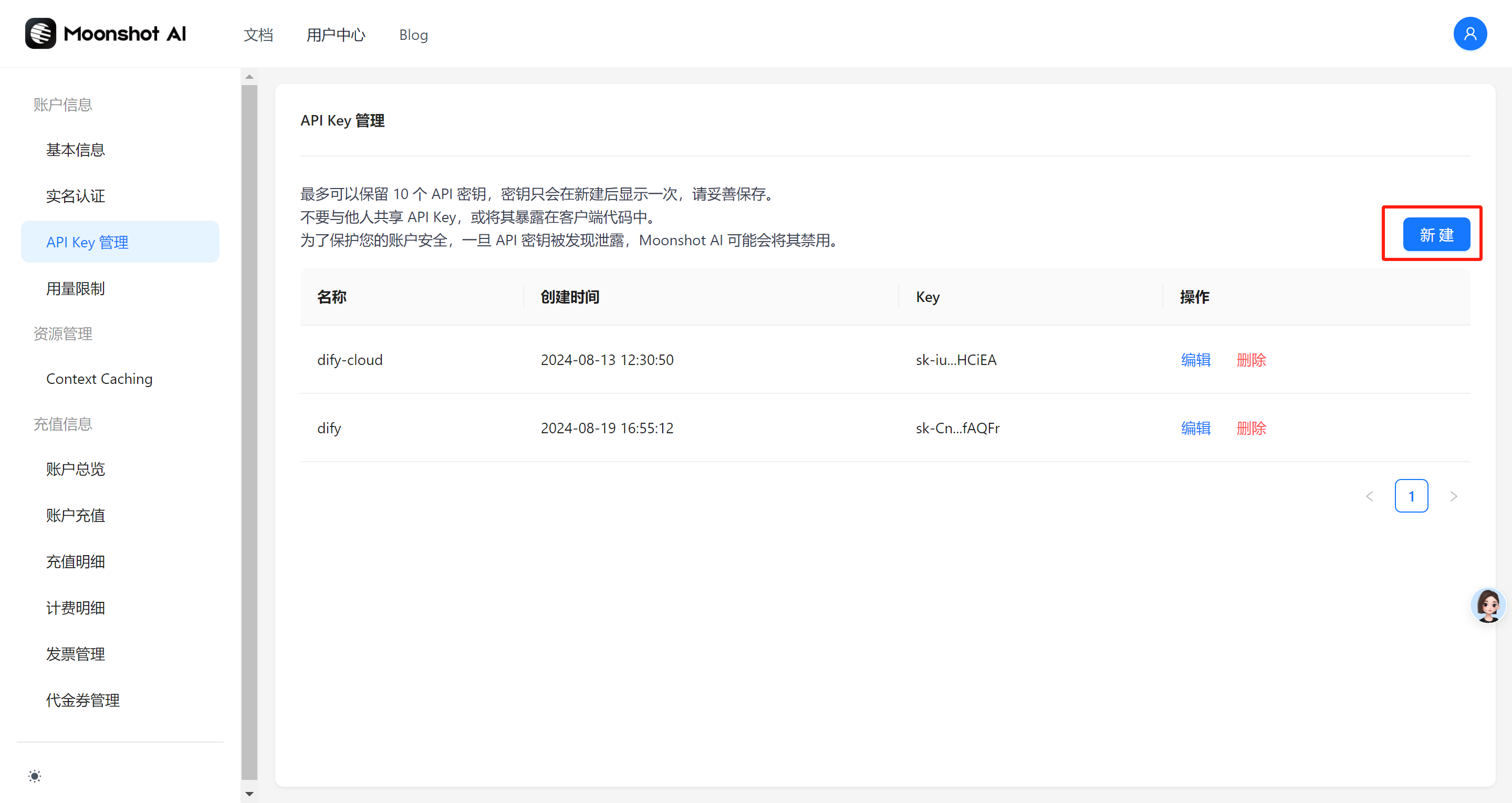
API接入成功后可以在模型供应商查看与开启
界面上方选项选择工作室,基础编排一个聊天助手。
关于聊天助手与Agent(AI 智能体),聊天助手(Chatbot)基于 LLM 构建对话式交互的助手,入门级及市面上大部分AI都是基于此,注重与人交互,需要人为主动输入触发进行提供信息、回答问题、解决疑惑等。AI Agent被定义为能够主动感知环境、进行决策和执行动作的智能实体。具备自主性和自适应性,在特定任务或领域中能够自主地进行学习和改进。我不认为这是两个独立的个体,Agent可以看作更高层次的发展方向,基础与前提仍需理解人类的各项指令和意图,再去实现更多的职责,当然Agent仍需有自主性,可以在没有人类干预的情况下运行,独立做出决策并执行这些决策。如无人驾驶汽车或无人机。
开始编排聊天助手,在提示词中可以描述你生成自己的聊天助手类型,如IT专家,网络安全专家。
如果没想好生成什么类型的聊天助手不妨看看这个Github 110K的项目 awesome-chatgpt-prompts
这个集合提供了非常多AI助手提示词(prompt)。
https://github.com/f/awesome-chatgpt-prompts
开启“视觉”,即运行用户输入图片来与聊天助手进行对话。
添加更多的功能,如自定义聊天助手的开场白。
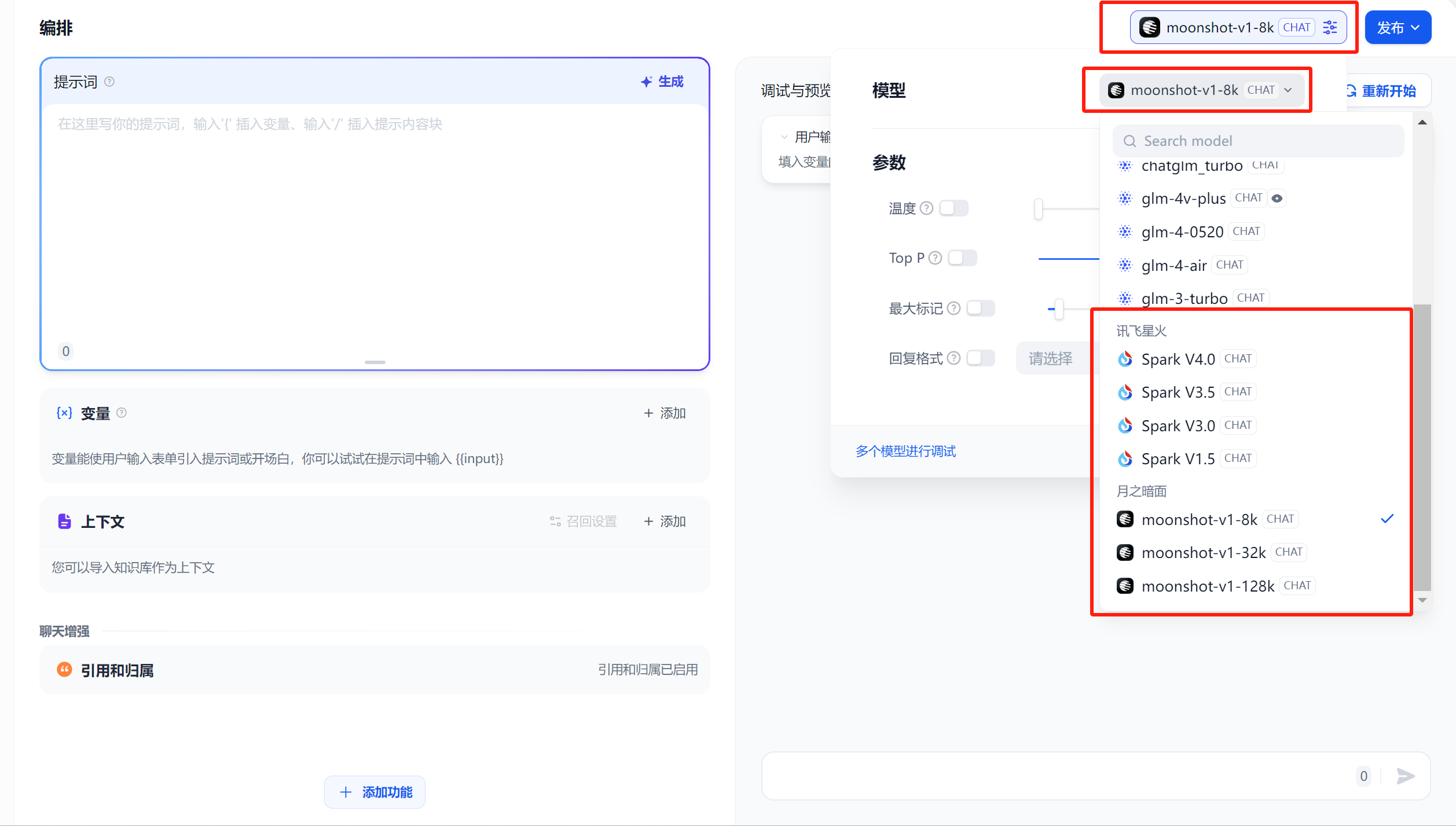
右侧选择聊天助手使用的模型
最后点击发布即可,来看看效果。探索可以直接在工作区使用。
同样,我们也可以将其以独立页面运行,特别是在使用云平台的dify,或是进行RAG知识库问答时。
搭建本地大模型
如果需要搭建企业内部知识库,基本离不开本地大模型的搭建,本地离线大模型可以保证内部数据的安全性,
Ollama
Ollama 是一个工具和平台,专门用于运行和管理大型语言模型(LLM)。它简化了模型的部署和使用,特别适用于那些没有太多资源或技术背景的用户,使他们能够轻松访问和操作强大的 AI 模型。Ollama 允许用户通过简化的界面和 API 来加载和使用模型,避免了手动配置和部署的复杂性。
Ollama模型库常见模型
| Model | Parameters | Size | Download |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
模型选择
本地模型可以参照hugging face开源大模型排行
- 模型用途:
- Text:通常是用于生成一般性的文本,例如文章写作、文本补全等。这类模型可能会有较为开放的文本生成能力。
- Instruct:这种模型是专门用来处理指令或任务导向的输入(例如问答、步骤指导等),通常在遵循指令方面表现更好。
- Chat:这种模型针对对话进行了优化,适用于聊天机器人、实时问答等场景。
- 模型精度:
- fp16(16位浮点数)模型:这种模型在计算时使用的是16位浮点数,通常比32位浮点数模型更节省内存,同时在精度损失不大的情况下提升性能。适合在内存有限的环境中使用。
- int8 或 q4_k_m:这些模型是量化过的模型,通过减少模型参数的位数来降低内存占用和计算需求,通常用于资源受限的设备,但可能会牺牲一些精度。大内存模型的高量化模型也会比小内存模型性能强一些。
- 性能与资源需求:
- 如果希望在设备资源有限(如边缘计算设备)下运行,选择更低内存占用的量化模型(如q4_k_m)是比较好的选择。量化程度越高,性能需求更低,模型的能力越差,如q2_k这种数字越低所需性能越低,随之性能也会越差。
- 如果资源充足且希望获得最高的模型表现,选择精度更高的模型如fp16。
总结来说:
- 如果关注模型在指令或任务执行上的表现,可以选择
instruct。 - 如果主要用于对话或者开放式生成,可以选择
text或chat。 - 如果计算资源有限且对模型速度有要求,可以考虑
fp16或量化版本的模型(如q4_k_m)。
具体示例
1. Instruct-fp16:
- 精度:使用 16 位浮点数(fp16)进行计算。相比原始的 32 位模型,fp16 模型在精度上可能会有微小损失,但通常不影响大多数任务的效果。
- 性能:fp16 模型比 32 位模型快得多,因为它在计算时减少了内存带宽和存储需求。因此,这种模型在拥有较好硬件的系统上可以提供更高的速度和效率,特别是在 GPU 上运行时表现优异。
- 效果:对比原始模型,fp16 模型在大多数情况下效果相似,尤其是在模型的推理任务上。
2. Instruct-q8_0:
- 精度:q8_0 表示模型已经量化到 8 位,这种量化会显著降低模型的内存占用和计算需求,但会对模型的精度产生一定的影响。量化模型在复杂任务(如生成高质量的自然语言文本)中可能会表现出一些劣化,尤其是在细微的文本生成任务中。
- 性能:由于模型的量化,q8_0 模型的运行速度和效率更高,非常适合在资源受限的环境中使用,如边缘设备或老旧的计算硬件上。
- 效果:虽然 q8_0 模型的效果在一些简单任务上仍然不错,但在复杂任务中,尤其是需要高精度生成的场景下,效果可能不如 fp16 或原始模型。
3. 原始 8B 模型:
- 精度:原始的 8B 模型通常是基于 32 位浮点数进行计算,提供最高的精度。特别是在细微的任务或需要复杂语言理解的场景中,原始模型的效果是最好的。
- 性能:由于使用 32 位浮点数计算,原始模型的计算量大,内存需求高,速度较慢,尤其是在没有足够硬件支持的情况下表现更为明显。
- 效果:原始模型的生成效果通常是最好的,特别是在复杂任务和需要高保真输出的场景下。
什么是 RAG(Retrieval-Augmented Generation)?
RAG 是一种结合信息检索与文本生成的架构,旨在利用外部知识库来增强生成模型的能力。它首先从一个知识库中检索相关文档,然后使用生成模型(如 GPT 或 BERT)结合这些文档的信息来生成答案或文本。这种方法可以显著提升生成的准确性和丰富度,因为它将大量外部知识融入到生成过程中。
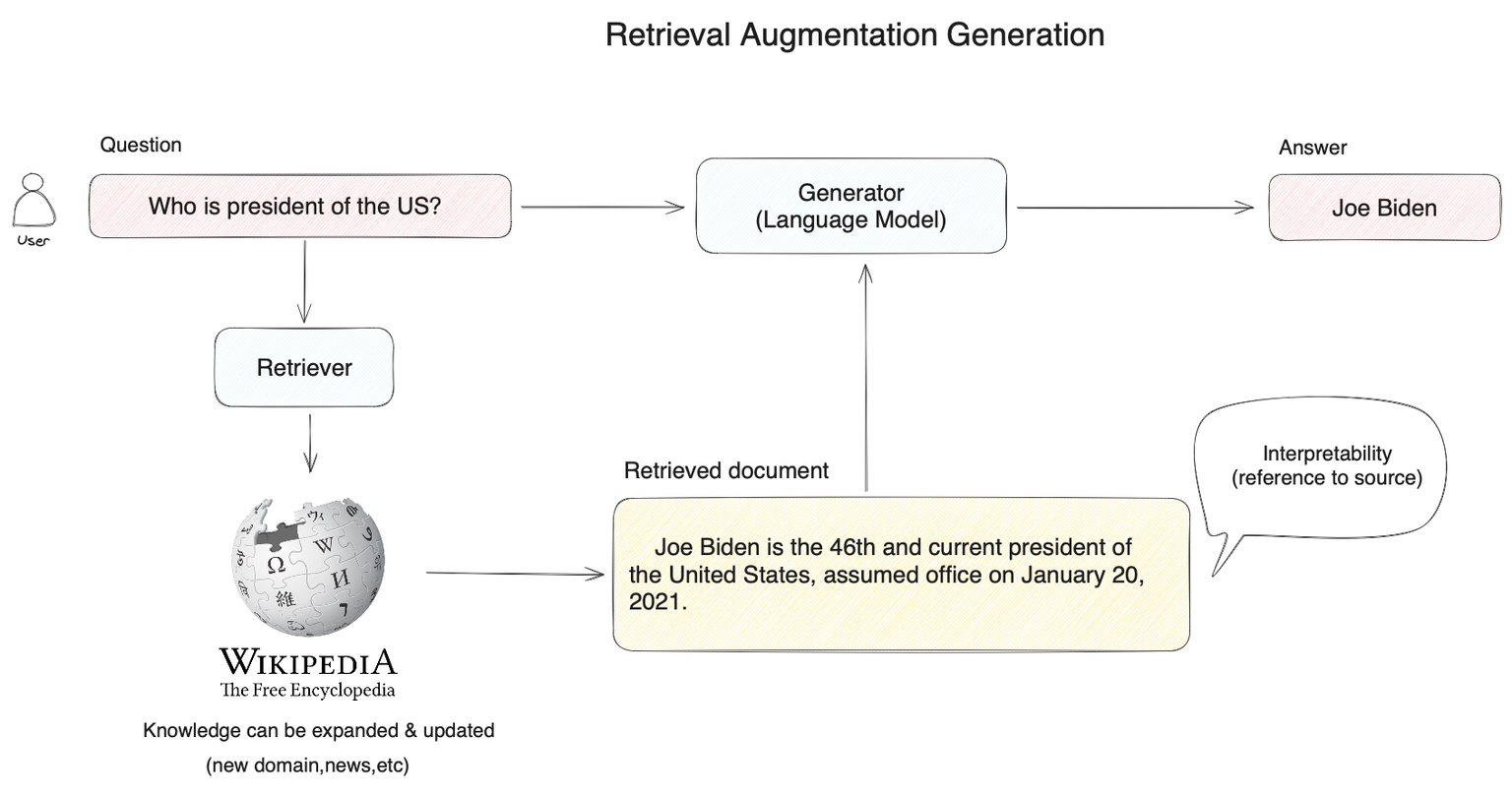
Embedding模型
Embedding 模型是一种用于将高维数据(通常是离散的文本、图像或其他符号数据)转换为低维连续向量表示的模型。Embedding 在自然语言处理 (NLP) 和计算机视觉等领域中应用广泛,主要目的是将复杂的数据结构映射到一个连续的向量空间,以便于进行相似性计算、聚类、分类等任务。
Embedding 模型在 RAG 中的作用
Embedding 模型在 RAG 系统中主要用于以下几个方面:
- 文档检索(Document Retrieval):
- 在 RAG 中,生成答案的第一步是从知识库中检索相关文档。Embedding 模型通过将文本(如查询和文档)转换为向量表示,然后在向量空间中进行相似性搜索,来找到最相关的文档。这种向量表示捕捉了文本的语义信息,使得检索更加精确。
- 查询与文档的匹配:
- 通过使用 Embedding 模型,RAG 系统可以计算查询和知识库中文档的向量相似度,选择最相关的文档进行进一步处理。通常使用余弦相似度或其他距离度量方法来评估查询与文档之间的相关性。
- 构建知识库:
- 知识库中的文档或信息通常也会使用 Embedding 模型进行预处理,生成嵌入向量。这些向量存储在数据库中,方便快速检索。知识库的规模可以很大,包括百科全书、技术文档、产品手册等多种类型的数据。
- 增强生成模型:
- 一旦检索到相关文档,生成模型将这些文档的信息与输入的查询结合起来,生成更加丰富和准确的文本输出。Embedding 模型通过确保检索到的文档与查询高度相关,间接提高了生成模型的表现。
RAG 的工作流程:
- 输入查询:用户输入一个查询,比如一个问题或任务描述。
- 查询嵌入:将查询通过 Embedding 模型转换为一个向量表示。
- 文档检索:在预先嵌入的知识库中,通过查询向量与文档向量的相似度,检索出最相关的文档。
- 生成回答:使用生成模型结合检索到的文档内容生成最终的回答或文本输出。
Embedding 模型对 RAG 系统的影响:
- 提高检索效率:嵌入向量的使用大大加快了检索的速度,尤其是当知识库非常庞大时。与传统基于关键词的检索方法相比,Embedding 模型可以更好地理解查询的语义,从而检索到更相关的文档。
- 增强语义理解:通过 Embedding 模型的语义能力,RAG 系统能够更好地理解复杂的查询,尤其是在多义性或上下文依赖性较强的查询中,能够更准确地选择相关信息。
- 提升生成质量:检索到的文档质量直接影响生成模型的输出。Embedding 模型通过优化检索过程,间接提升了生成结果的质量,使得生成的文本更加连贯、相关和有用。
如何选择Embedding模型
MTEB (Massive Text Embedding Benchmark) 是一个用于评估文本嵌入模型(Text Embedding Models)性能的基准测试平台。它通过大量的任务和数据集,对不同的文本嵌入模型进行全面的性能评估。MTEB 的设计目的是提供一个统一的标准来比较和分析不同文本嵌入技术的优劣,使研究者和开发者能够更好地选择和优化模型。
MTEB 的特点和关键要素:
- 多任务评估:
- MTEB 涵盖了多种任务类型,包括文本分类、相似性搜索、聚类、排序等。每种任务代表了文本嵌入模型在特定应用场景下的表现,例如情感分析、话题分类、文档匹配等。
- 多数据集:
- MTEB 使用了多种公开可用的数据集,这些数据集涵盖了不同领域和不同语言的数据。这使得 MTEB 能够全面评估模型在各种语言和任务上的表现。
- 统一的评估标准:
- MTEB 提供了统一的评估标准和指标,如准确率、F1 分数、平均精度等。这些指标使得不同模型的评估结果具有可比性。
- 多维度分析:
- MTEB 不仅评估模型的总体表现,还提供了对不同任务、数据集和指标的细粒度分析。研究者可以通过这些分析更深入地理解模型的强项和弱项。
- 适用范围广:
- MTEB 适用于各种文本嵌入模型,包括传统的基于词袋(Bag-of-Words)方法、深度学习模型(如 BERT、GPT 等)以及最新的 Transformer 模型。它可以帮助研究者和开发者在选择模型时做出更明智的决定。
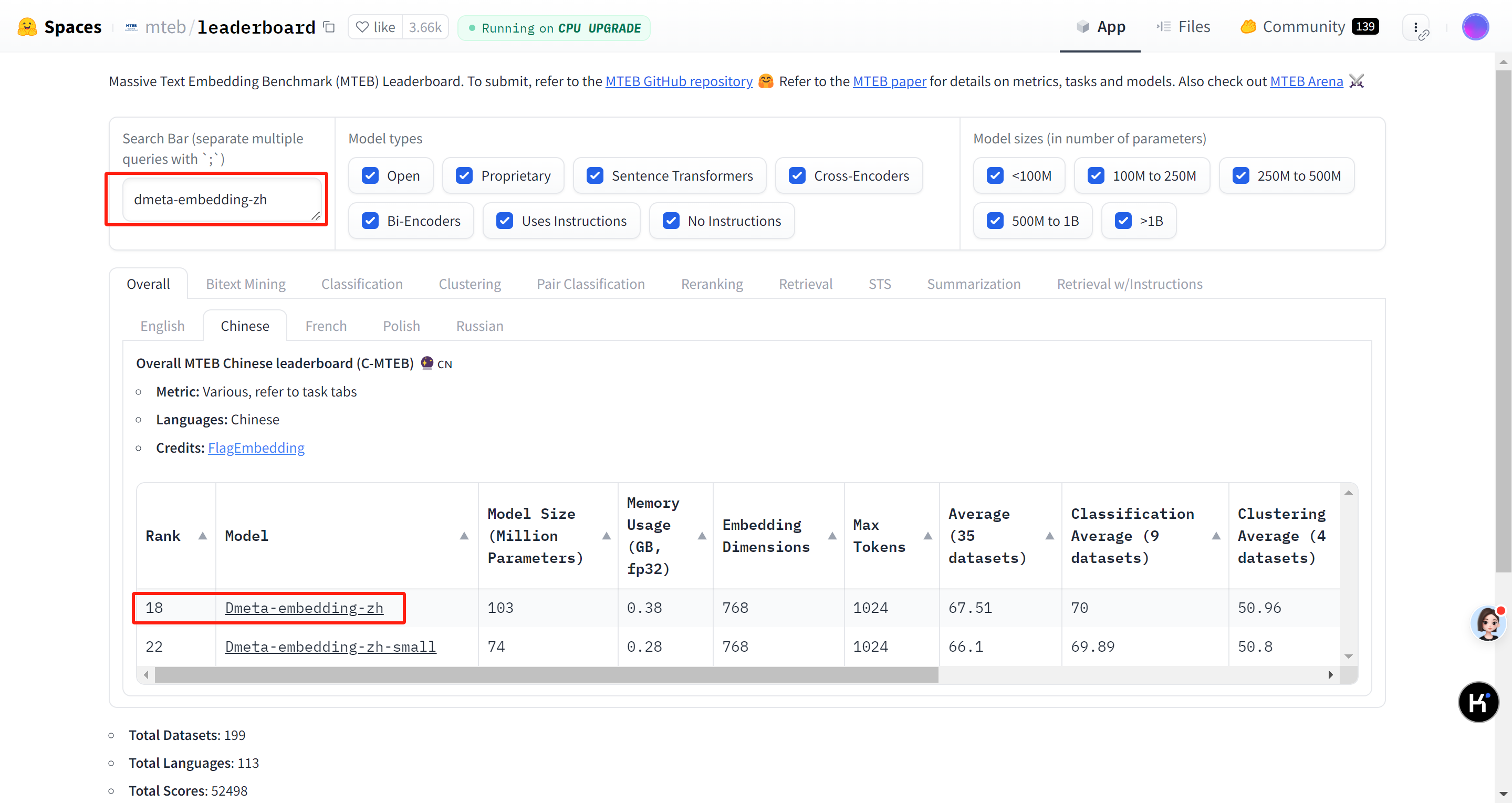
hugging face网站上的Embedding模型排名
MTEB(MassiveTextEmbeddingBenchmark)
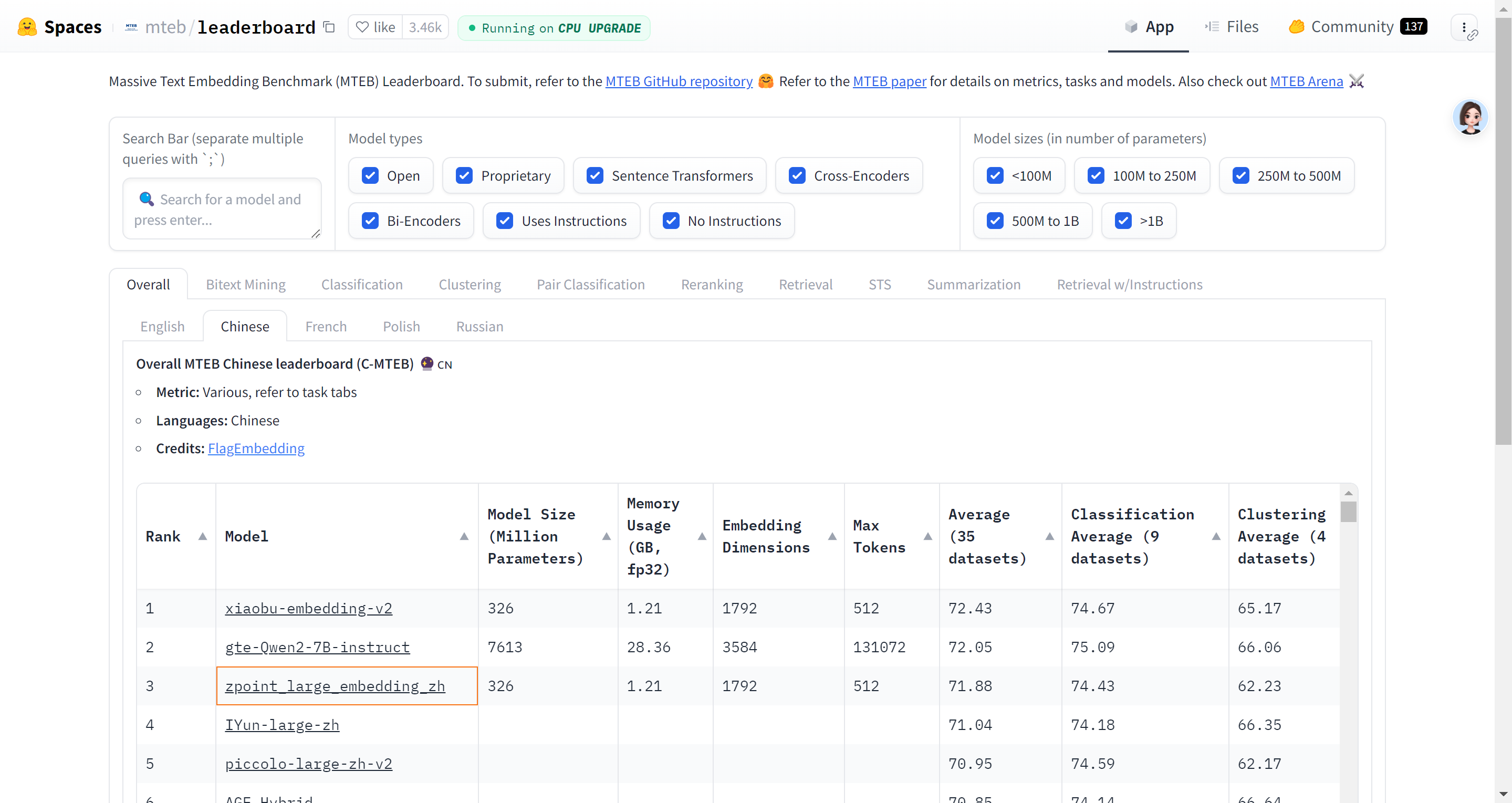
选择用于中文Embedding的模型
什么是 Rerank 模型?
Rerank模型是用于对初始检索结果进行二次排序的模型。初始检索阶段通常返回多个候选文档,这些文档根据查询的相关性进行了初步排序。然而,由于初始检索模型(如基于向量的检索模型)可能只考虑了查询与文档的粗略相似性,结果中可能存在噪音或不够相关的文档。Rerank模型在这种情况下通过更深入的语义分析或更复杂的特征组合,对这些候选文档进行二次排序,以提升排序结果的准确性和精度。
Rerank 模型的工作原理
- 初步检索:首先,信息检索系统(如基于Embedding的检索系统)会根据用户查询在大规模文档集合中检索出一组相关性较高的文档。通常,这些文档的数量会比最终展示的结果多得多(比如100个候选文档)。
- Rerank 过程:
- 特征提取:Rerank模型会对每个候选文档提取更多的特征,这些特征可能包括词汇匹配、句法结构、上下文信息等。
- 模型打分:根据提取的特征,Rerank模型为每个文档生成一个新的相关性得分。这个过程可能使用复杂的机器学习模型(如深度学习模型)来捕捉文档与查询之间的深层次语义关系。
- 重新排序:根据新的得分,对候选文档进行重新排序,从而提高最终输出文档的相关性。
- 输出结果:最终,系统展示或使用重新排序后的前几个文档。
Rerank 模型的实现技术
- 基于传统特征的 Rerank:
- 使用一些简单的特征,如BM25得分、词频、逆文档频率(TF-IDF)等进行二次排序。这种方法较为简单,但在语义复杂的查询下效果有限。
- 基于深度学习的 Rerank:
- 使用BERT、RoBERTa等预训练语言模型来提取更丰富的语义特征,并进行二次排序。深度学习模型能够更好地捕捉文档与查询之间的复杂语义关系,从而显著提升排序效果。
- 多模态 Rerank:
- 在处理多模态数据(如图文结合)时,可以使用多模态 Rerank 模型,将文本与其他类型的数据结合起来进行排序。